컴파일러 전반부 구조

-Lexical Alalysis
어휘분적
- 원시프로그램을 긴 문자열로 보고 차례대로 문자를 검사하여, 의미있는 최소단위들로 변환하는 것
-Space 같은 것들을 제거해 결과적으로 코드를 줄임
Token: "문법적으로 의미 있는 최소단위"
정규표현식을 인식하는 유한상태오토마타(FSA)를 상태전이도로 표시해보기
token과 관련된 질문들 답하기
1) How to describe tokens?
2) How to recognize tokens?
3) How to break up tokens?
4) How to represenet toknes?
-1 Token을 어떻게 표현할 것인가? -> 정규표현식
리눅스 정규 표현식 종류 링크
[LINUX] 📚 정규표현식 과 grep 명령어 정복하기 [패턴 검색] [확장브래킷]
파일/디렉토리 패턴 검색 리눅스를 사용하다 보면 로그파일이나, 텍스트 파일에서 특정 문자열을 찾을 때, 혹은 디렉터리 내에서 특정 문자를 포함하는 파일을 찾을 때와 같은 경우가 생긴다.
inpa.tistory.com
자바 정규 표현식 종류 링크
[Java] 정규표현식 사용법 및 예제 - Pattern, Matcher
자바에서 정규표현식(Regular Expression)'을 사용해보자. 1. 정규표현식(Regular Expression) 정규표현식 혹은 정규식은 특정한 규칙을 가진 문자열의 집합을 표현하는데 사용되는 언어다. 정규 표현식은
hbase.tistory.com
메타문자들 설명 이게 중요 !@! @ @ ! 링크
정규표현식 (regex)
정규 표현식 정규표현식(regular expression)은 일종의 문자를 표현하는 공식으로, 특정 규칙이 있는 문자열 집합을 추출할 때 자주 사용되는 기법입니다. 주로 Prograaming Language나 Text Editor…
sooftware.io
1. a로 시작하는 식별자 a[a-zA-Z0-9]
2. 2진수중 4의 배수
100
1000
1100
10000
10100 -> (1(1|0))100 x 1000, 10000
->(1(1|0))+00
3. 식별자중 a 와 b의 갯수가 동일하게 나타나는 것
정규식 테스트 하기
4.[abc] 와 abc 의 차이점 전자는 a or b or c abc는 그냥 abc
5. [^abc]는 a와 b와 c를 제외한 모든 문자 하나, [abc^]는 a or b or c or "^", ^abc는 라인의 시작에 abc
6.[a-z] 와 [-az]와 [az-] -> 1은 영어 소문자, 2,3 는 or
7.[] 는 다른 메타기호가 들어가 있지 않다면 다 or이다
[a|b]는 a or "|" or b , (a|b)는 a or b
regex101: build, test, and debug regex
Regular expression tester with syntax highlighting, explanation, cheat sheet for PHP/PCRE, Python, GO, JavaScript, Java, C#/.NET.
regex101.com
-2 token을 어떻게 인식할 것인가
정규표현식을 어떤 방식으로 식별하는가 -> 유한 상태 오토마타 FSA
정의
*상태를 유한한 갯수까지만 가짐
*상태 간의 전이를 정의함
*시작 상태 한 개(start)와 끝 상태 여러 개(O 두개)를 가짐
정규표현식은 FSA로 표현가능 FSA는 정규표현싱으로 표현 가능
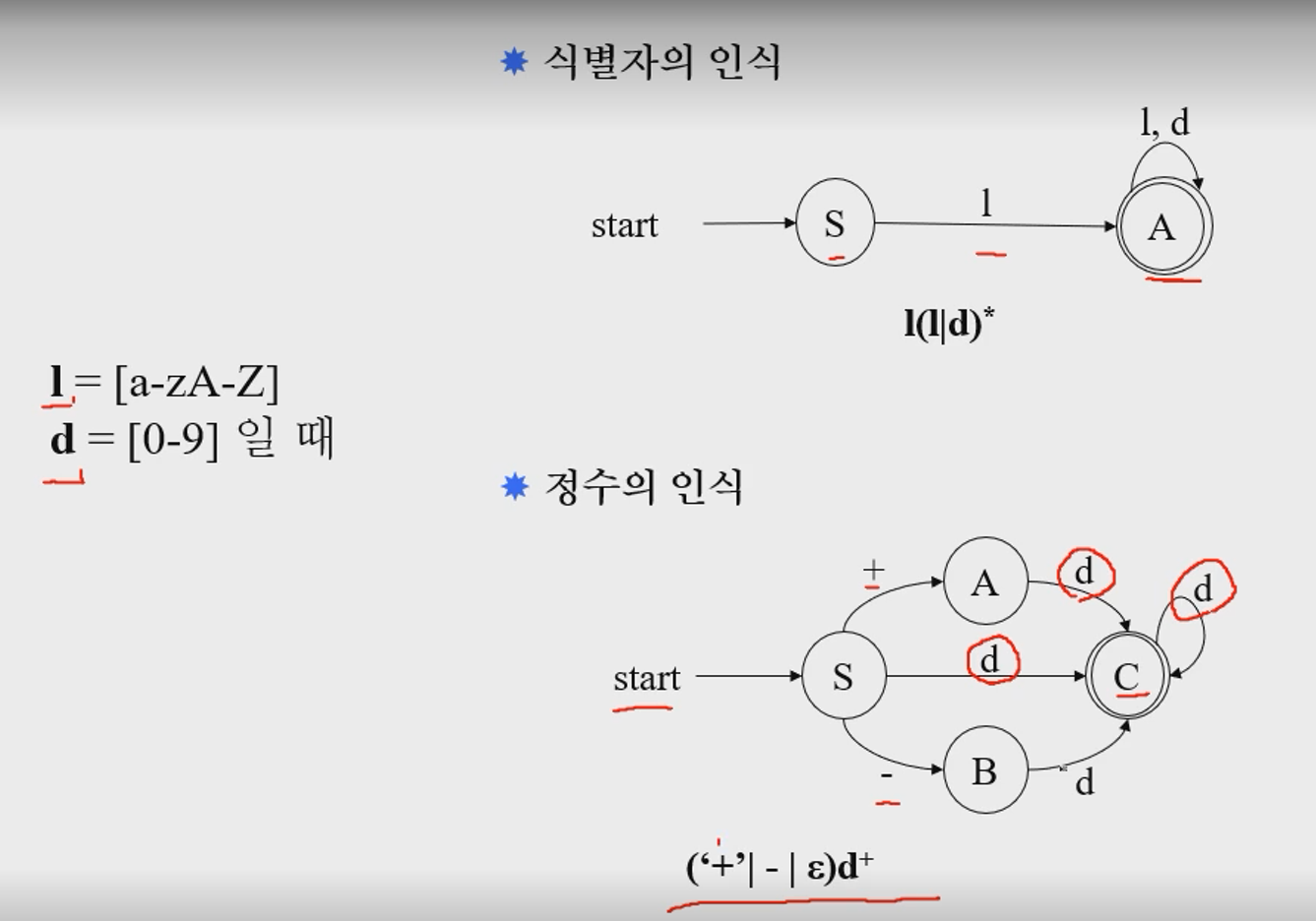
d+ 반복
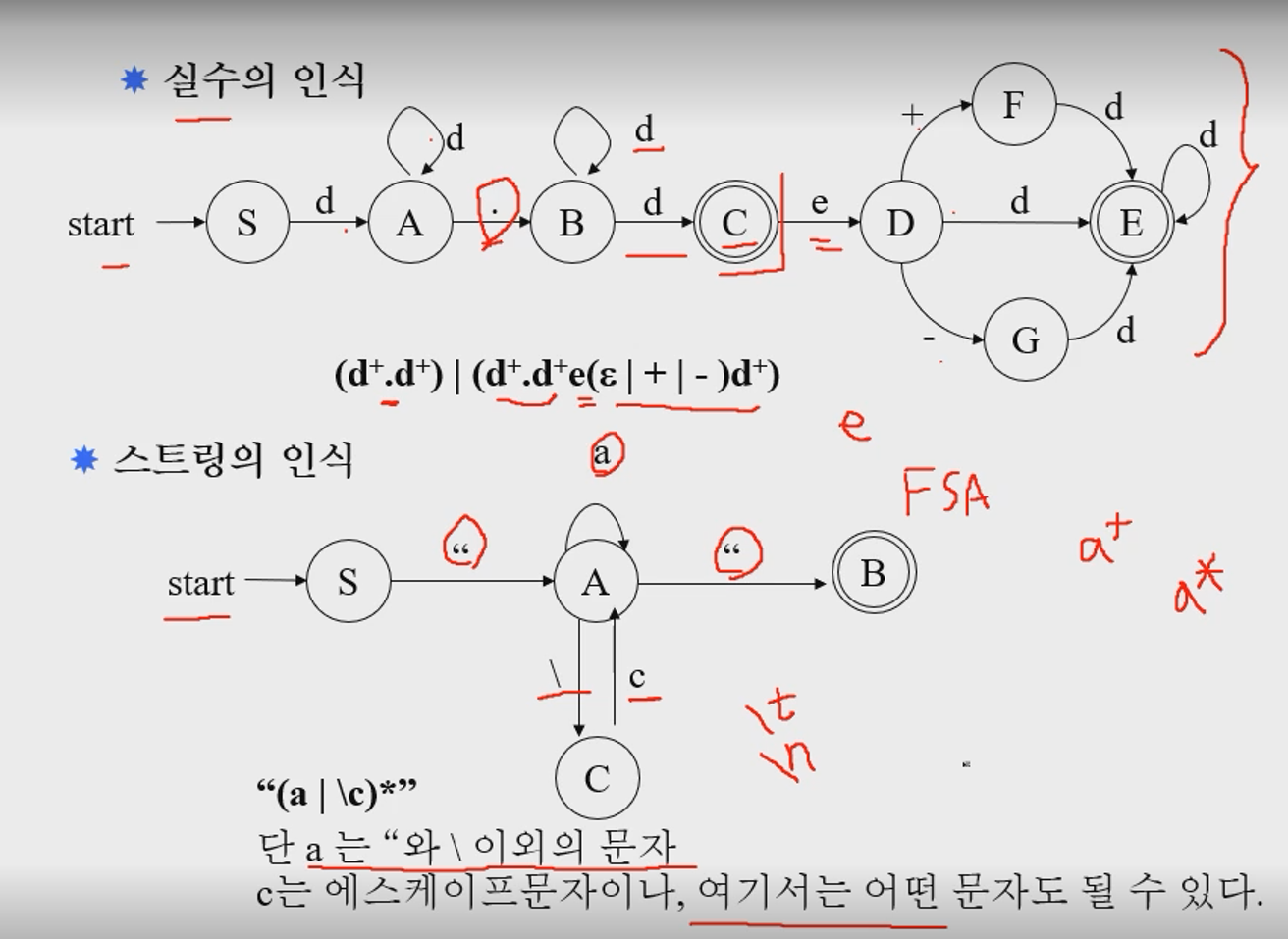
그래서, 토큰인식은
정규표현식을 NFA(non-dfa)로 변환시키고 다시 NFA를 DFA로 변환시키고 이 DFA를 따라 인식한다.
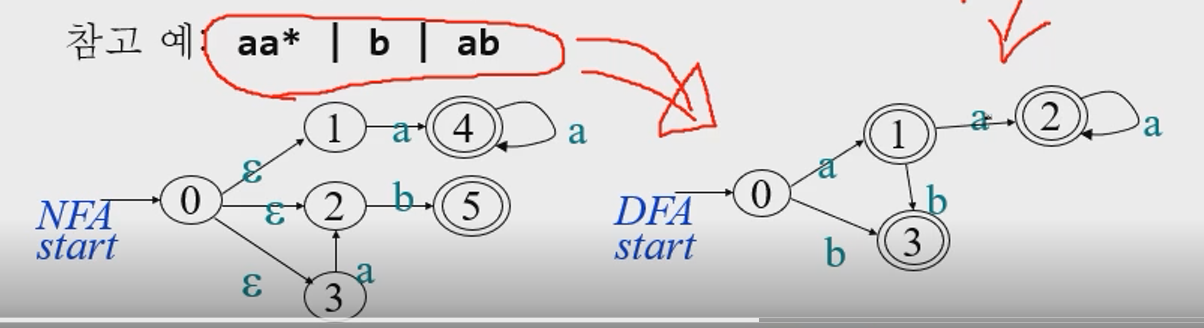
-3 text를 어떻게 나눌 것인가?
긴 token 우선 !
-4 token을 어떻게 표현할 것인가.
Lexeme = <토큰번호, 토큰값>
-토큰번호 : 각 토큰들을 효율적인 처리하기 위해서 고유의 내부번호
-토큰값: 토큰이 프로그래머가 사용한 값을 가질 때 그 값을 말한다., 명칭의 토큰값은 그 자신의 스트링 값, 상수의 토큰값은 그 자신의 상수 값
어휘분석기 도구 Lex
사용자가 정의한 정규표현과 실행코드를 입력 받아 C언어로 쓰여진 프로그램 출력
전에 했던 HulToC컴파일러가 어휘분석기이다.
lex의 선택규치
- 가장 길게 인식된 토큰을 우선으로 한다.
-인식될 수 있는 토큰의 길이가 같은 경우 먼저 나타난 규칙의 정규 표현으로 인식한다.
'3-2 > Compiler Introduction' 카테고리의 다른 글
| [컴파일러 개론]LL 파싱과 FIRST, FOLLOW (0) | 2022.09.19 |
|---|---|
| [컴파일러 개론] 구문 분석기 (0) | 2022.09.15 |
| [컴파일러 개론] 컴파일러 만들기(2) (0) | 2022.09.10 |
| [컴파일러 개론] 컴파일러 만들기(1) (0) | 2022.09.05 |
| 컴파일러 개론 1주차 2022.09.01 (0) | 2022.09.01 |